Python/크롤링
크롤링 여러페이지의 데이터 가져오기
GinaKim
2024. 1. 31. 22:30
728x90
네이버 주식 페이지에서 종목별로 모든 페이지의 데이터 표 가져오기
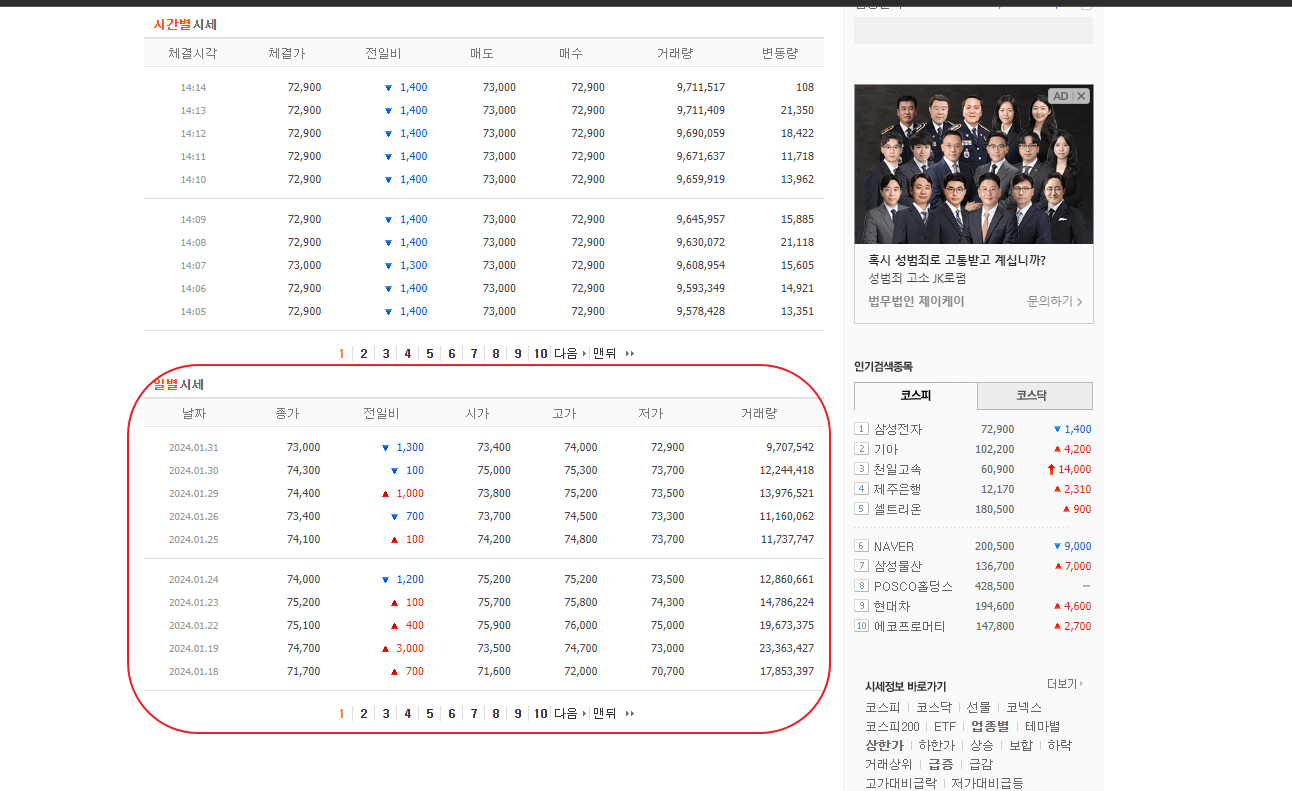
개발자 도구에서 해당 표에 대한 링크만 뽑을 수 있는 점 참고
1. pd.read_html을 사용해서 테이블 불러오기
pd.read_html을 이용하면 html에 있는 table 속성에 해당하는 값을 가지고 올 수 있다.
pandas.read_html(URL, match='.+', flavor=None, header=None, index_col=None, skiprows=None, attrs=None, parse_dates=False, tupleize_cols=None, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None, keep_default_na=True, displayed_only=True)
import requests
import pandas as pd
from bs4 import BeautifulSoup
import warnings
import time
import random
warnings.filterwarnings('ignore')
company_code = '005930' # 삼성전자
url ="https://finance.naver.com/item/sise_day.nhn?code=" + company_code
headers = {
'referer' : 'https://finance.naver.com/item/sise.naver?code=005930',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
result = pd.read_html(response.text, encoding='euc-kr')[0]
result
pd.read_html()을 사용하면 리스트 안에 데이터프레임이 들어있는 형태로 html에 있는 모든 table을 한번에 가져온다.
그래서 인덱스로 원하는 표를 불러옴

2. 모든 페이지의 테이블 불러오기
1. 우선 종목별 페이지마다 마지막 페이지를 불러올 수 있는 코드를 만든다

import requests
import pandas as pd
from bs4 import BeautifulSoup
import warnings
import time
import random
warnings.filterwarnings('ignore')
company_code = '005930' # 삼성전자
url ="https://finance.naver.com/item/sise_day.nhn?code=" + company_code
headers = {
'referer' : 'https://finance.naver.com/item/sise.naver?code=005930',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
result = pd.read_html(response.text, encoding='euc-kr')[0]
# 각 종목에 맞춰서 모든 페이지를 가져오도록 실행
soup = BeautifulSoup(response.content, "html.parser")
last_page = int(soup.select_one('td.pgRR').a['href'].split('=')[-1])
last_page
- select_one('td.pgRR'): 이 부분은 CSS 선택자 'td.pgRR'에 해당하는 첫 번째 요소를 선택합니다. td.pgRR는 HTML 문서 내에서 <td> 태그 중에 class 속성이 'pgRR'인 요소를 의미합니다.
- .a: 이 부분은 선택된 <td> 태그에서 <a> 태그를 찾아내기 위한 부분입니다. .a는 BeautifulSoup에서 Tag 객체의 속성 중 하나로, 해당 태그의 자식 태그 중에서 첫 번째 <a> 태그를 가져옵니다.
- ['href']: 이 부분은 선택된 <a> 태그의 href 속성 값을 가져옵니다. ['href']는 Tag 객체의 속성 중에서 'href'에 해당하는 값을 반환합니다.
2. 페이지별로 표를 뽑아내고 표들을 합칠 수 있는 반복문을 만든다.
로딩이 너무 오래 걸려서 if문으로 페이지를 3페이지까지로 제한함
import requests
import pandas as pd
from bs4 import BeautifulSoup
import warnings
import time
import random
warnings.filterwarnings('ignore')
def crawling(url, headers, soup):
last_page = int(soup.select_one('td.pgRR').a['href'].split('=')[-1])
df = None
# count = 0
for page in range(1, last_page + 1):
req = requests.get(f'{url}&page={page}', headers=headers)
df = pd.concat([df, pd.read_html(req.text, encoding = "euc-kr")[0]], ignore_index=True)
# if count > 3:
# break
# count += 1
time.sleep( random.uniform(2,4))
df.dropna(inplace=True)
df.reset_index(drop=True, inplace=True)
return df
def main():
company_code = '005930' # 삼성전자
url ="https://finance.naver.com/item/sise_day.nhn?code=" + company_code
headers = {
'referer' : 'https://finance.naver.com/item/sise.naver?code=005930',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
result = pd.read_html(response.text, encoding='euc-kr')[0]
soup = BeautifulSoup(response.content, "html.parser")
a = crawling(url, headers, soup)
print(a)
if __name__ == "__main__":
main()
코드를 실행하면 결과가 이렇게 나온다

728x90