728x90
Label Encoding
카테고리 피처를 코드형 숫자 값으로 변환하는 것
1. 카테고리 피처 코드형 숫자값으로 변환
from sklearn.preprocessing import LabelEncoder
items=['TV','냉장고','전자레인지','컴퓨터','선풍기','선풍기','믹서','믹서']
# LabelEncoder를 객체 생성, fit, transform으로 Label 인코딩 수행
# 종속변수에 적용
# 수치 예측할 때, LabelEncoder 사용 (ㅌ)
# 범주 예측 : 예시, 양성 / 음성 / 잘 모르겠음
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)
labels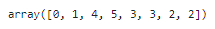
2. 문자열 값이 어떤 숫자 값으로 인코딩 됐는지 확인
LabelEncoder 객체의 classes_ 속성값으로 확인하면 됨
encoder.classes_
3. 인코딩된 값을 다시 디코딩
inverse_transform() 활용
encoder.inverse_transform([4, 5, 2])
레이블 인코딩은 간단하게 문자열 값을 숫자형 카테고리 값으로 변환함.
숫자 값의 경우 크고 작음에 대한 특성이 작용하기 때문에, 몇몇 ML알고리즘에는 이를 적용할 때 예측 성능이 떨어지는 경우가 발생할 수 있음
(ex. 냉장고가 1, 믹서기가 2로 변환되면, 1보다 2가 더 큰 값이므로 특정 ML알고리즘에서 가중치가 더 부여되거나 더 중요하게 인식할 가능성이 발생)
이러한 특성 때문에 레이블 인코딩은 선형회귀와 같은 ML알고리즘에는 적용되지 않아야 함!!
트리계열의 ML 알고리즘은 숫자의 이런 특성을 반영하지 않으므로 레이블 인코딩도 별 문제 없음!!
One-Hot Encoding
레이블 인코딩의 단점을 보완한 인코딩 방식
피처값의 유형에 따라 새로운 피처를 추가해 고유값에 해당하는 칼럼에만 1을 표시하고 나머지 칼럼에는 0을 표시하는 방식
사이킷런에서 OneHotEncoding 클래스로 변환이 가능
다만, 주의할 점이 있음
- 입력값으로 2차원 데이터가 필요
- OneHotEncoder를 이용해 변환한 값이 희소행렬(sparse matrix) 형태이므로 이를 다시 toarray() 메서드를 이용해 밀집행력 (Dense Matrix)로 변환해야 함
from sklearn.preprocessing import OneHotEncoder
import numpy as np
items=['TV','냉장고','전자레인지','컴퓨터','선풍기','선풍기','믹서','믹서']
# 2차원 ndarray로 변환한다.
items = np.array(items).reshape(-1, 1)
print(items.shape)
# 원-핫 인코딩을 적용
oh_encoder = OneHotEncoder()
oh_encoder.fit(items)
oh_labels = oh_encoder.transform(items)
oh_labels.toarray()
get_dummies()
판다스의 get_dummies().를 사용하면 원-핫 인코딩을 더 쉽게 사용 가능
사이킷런의 OneHotEncoder과는 다르게 문자열 카테고리 값을 숫자형으로 변환할 필요 없이 바로 변환 가능
import pandas as pd
df = pd.DataFrame({'item':['TV','냉장고','전자레인지','컴퓨터','선풍기','선풍기','믹서','믹서'] })
pd.get_dummies(df)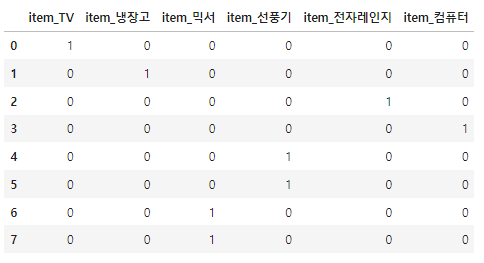
728x90
'머신러닝' 카테고리의 다른 글
| [머신러닝] 분류분석 평가 지표 - 오차행렬, ROC (0) | 2024.02.20 |
|---|---|
| [머신러닝] 피처스케일링 - StandardScaler, MinMaxScaler (0) | 2024.02.19 |
| [머신러닝] 하이퍼파라미터 최적화 방법 GridSearchCV vs RandomizedSearchCV (0) | 2024.02.19 |
| [머신러닝] K-폴드 교차 검증, stratified K폴드(층화추출) (0) | 2024.02.14 |
| [머신러닝] 사이킷런 활용하여 붓꽃 품종 예측하기 (0) | 2024.02.14 |